I was in Europe for the past week and half, ending up in Leuven, Belgium to speak at the Twiist.be conference. The topic of my talk was “The Open, Social Web.” (PDF)
At first I struggled to develop a compelling or sensible narrative for the talk — as there is so much to it that I could probably give a dozen or more 45 minutes talks on the subject. With some long-distance encouragement from Brynn, I eventually arrived at the topic I wanted to cover that lead to a conclusion that has largely been implicit in my work so far.
My first priority was to establish that Web 2.0 is not only still the defining paradigm of this period, but that its core assertions are only now beginning to be realized and that much work still remains. Indeed, Tim O’Reilly’s original intention with “Web 2.0” was to encourage open source developers to begin to see the web as a platform — and to move beyond “the page metaphor of Web 1.0 to deliver rich user experiences.”
Considering Tim O’Reilly’s advocacy of and publishing business largely founded on open source principles, his advocacy of Web 2.0 as a business revolution (a shift away from the personal desktop as the primary development platform) is significant.
But what I think has gone missing is a coherent narrative or recasting of “open source” in the Web 2.0 era. After joining the Firefox movement, I learned the fundamentals of open source by reading “Tim O’Reilly in a Nutshell” (PDF). That book was never updated to capture how the principles of freedom of access and competitive and meritocratic marketplaces apply in the age of cloud computing.
As Matt Asay recently observed, gone are the days of the ‘ideologues’ … “100-percent freedom” litmus test’. In other words, advocating for open source in the era of cloud computing is no longer sufficient to ensure the kind freedom that people like Richard Stallman sought.
 Moreover, the term “open” itself is being debased, being used in pop-marketing campaigns to connote crowd-sourced and “conversationy” marketing — things that have nothing to do with the freedom desired by open source proponents. Thomas Jefferson (or John Philpot Curran) got it right when he said that the “price of freedom is eternal vigilance.” We can’t fight for open if we don’t have a testable definition of what “open” means.
Moreover, the term “open” itself is being debased, being used in pop-marketing campaigns to connote crowd-sourced and “conversationy” marketing — things that have nothing to do with the freedom desired by open source proponents. Thomas Jefferson (or John Philpot Curran) got it right when he said that the “price of freedom is eternal vigilance.” We can’t fight for open if we don’t have a testable definition of what “open” means.
For me, openness is about freedom of choice and unfettered access to compete in an open marketplace. To that end, you still must protect against monopolistic threats, which can jeopardize entry to markets and therefore require regulation.
Specifically, when I was in Paris, Bertil Hatt presented me with a few concepts from his Ph.D. work in economics that are necessary to defeat monopolies in social networks and cloud-based markets:
- data portability: related to switching costs; an example of this is phone number portability (which require government intervention to achieve)
- multi-homing: increasing reliability through parallelization; the example I used was ping.fm, which allows you to publish content simultaneously to multiple destinations, thereby defeating network exclusivity and lock-in
- roaming: have access to and using other people’s networks; I showed a text message that I received from AT&T explaining how they wanted to charge me $20/MB while roaming in Europe. Clearly networks don’t like it when their customers roam!
- disaggregation: service substitutability; in this case the photo-editing service Picnik imports photos from a multitude of sources, avoiding tightly coupling itself an any one particular service, unlike Facebook’s photo-sharing service, which can only be used and accessed on facebook.com.
And so if these are some of the concepts that we can use to arm ourselves in the fight for freedom and openness in the era of cloud computing, the opportunity to define a narrative and roadmap for “open cloud computing” emerges.
In my view, success in this effort will resonate most widely on the social web, where we’ve simply not yet achieved the potential of open source ecosystem of social applications.
Of course one of the challenges of making progress with developing the social web is that the web itself was originally conceived of as a means to share documents — not to express the manifestations of personal identity online.
Had the web originally been designed to connect people with people, and not just documents, I think that the work of startups like FriendFeed would be occurring at a much higher layer of abstraction. Instead, FriendFeed is having to manually develop many of its own technologies to address this shortcoming in the architecture of the web, and chief among what’s missing is a way to capture and express activities on the web — ostensibly the bread and butter of FriendFeed’s offering. Historically, the feed formats common on the web today (namely RSS and ATOM) were designed to express and capture what was common at the time of their creation: blog posts.
And so all kinds of data are syndicated in these formats, but without semantic hooks that express who the actor was, what the object of the activity was, and what it was they did that resulted in or affected the object.
 It’s holes like these that gave rise to the Diso Project: an effort to facilitate the creation of and adoption of building blocks (i.e. formats and protocols) for the social web.
It’s holes like these that gave rise to the Diso Project: an effort to facilitate the creation of and adoption of building blocks (i.e. formats and protocols) for the social web.
Though I revise the list from time to time, the fundamental components of the Diso Project have largely remained consistent:
- identity and profile
- discovery and access control
- contacts and friends
- activity streams
- messaging
- groupings and shared spaces
Of course, the project will only be considered successful if the formats and protocols developed are widely adopted: a standard in practice is worth more than a standard in theory.
Moreover, by commoditizing certain fundamental features, service providers will move to compete on the level of user experience and service, rather than on lock-in alone.
And in the distributed social model of the web, there is nothing more fundamental than establishing a means of expressing durable, cross-site identity.
 It is my contention that the individual is the basic atomic unit of society, and without society you can’t get to acting on the “social” layer. And since change only can begin at the scale of the individual, OpenID must occupy a cornerstone of the open, social web.
It is my contention that the individual is the basic atomic unit of society, and without society you can’t get to acting on the “social” layer. And since change only can begin at the scale of the individual, OpenID must occupy a cornerstone of the open, social web.
We’re beginning to see many more signs that real identity is something that people desire online — that having an online presence isn’t just for geeks and real estate agents anymore. People who want to connect with friends, family, long-lost school friends — and everyone and anything else — are coming online in droves to set up a digital presence.
In one example, I walked through the process of adding a friend on Facebook that the service recommended to me. Sure I could recognize my friend’s face and name — but was it really them? Through the magic of the social graph — and more importantly, the fact that so many of our mutual friends had let aspects of their real life identity slip into the digital public — I was able to confirm that, yes, this was the person that I thought it might be, because these were people that we were likely to both know.
Only a few years ago, this kind of social context was not available online because people had not yet become comfortable — or seen the value of — setting up a profile online — a process that I believe is a form of modern self-actualization, straight out of Maslow’s hierarchy of needs.
One consequence is that companies like Google, FriendFeed, Twitter, and Facebook are clambering over each other to meet this need, each providing convenient URLs for people to print on business cards and share with friends:
- facebook.com/chrismessina
- friendfeed.com/chrismessina
- google.com/profiles/chrismessina
- twitter.com/chrismessina
Referring to Tim O’Reilly’s thoughts on the business models of Web 2.0, new lock-in is achieved through either owning a namespace or accruing hard-replicate amounts of data. It’s not hard to see what’s going on here.
Worse, from my perspective, is that I have very little control over how I am presented by these services. Facebook gives me no control over my public profile (I can change my profile picture and choose how public or private I want to be); FriendFeed represents my activities online, but gives me no control over the look or priority of activities shown by default; Google lets me customize and control a great deal of what shows up on my page, but everyone’s page looks the same, as though we all worked for Google; finally, Twitter lets me customize the background image and colors of my profile, but without context or knowing about Twitter, it might be confusing just what’s going on or what I’m posting about.
That’s not to say that these services are doing anything wrong, only that the option for me to express myself as I choose should be provided without sacrificing my ability to use these services or to connect with their members, just as I’m able to host my own email server and send email to other email servers without pre-registering with them.
Now, it is true that, even I’m not able to self-host my own identity and connect with these services, there is much work being done to establish APIs that at least allow services to connect with one another — affording roaming, multi-homing, data portability, and service substitutability.
 The problem with the current — albeit transitional — approach is that it leads to what we’ve christened the “NASCAR problem” — the one where dozens of vendor logos dominate simple interfaces to “make it easier” for people to access and connect to their preferred provider.
The problem with the current — albeit transitional — approach is that it leads to what we’ve christened the “NASCAR problem” — the one where dozens of vendor logos dominate simple interfaces to “make it easier” for people to access and connect to their preferred provider.
I call this transitional because the NASCAR approach fundamentally does not scale and is not portable — that is, the brands that are known or popular in one market or geographic location may not be the same elsewhere and if you mess with the default set of logos, you’re liable to lock out one portion of your users who may well become dependent on seeing a logo that they recognize to connect or log in.
Now, for some providers, I’m sure that would be a desirous outcome, but to my overall theme, that’s not the level of competition that I think we should be focusing on. Time has proven that lock-in never results in better services or more satisfaction and is ultimately not good for the marketplace. At best, it’s temporarily good for a few dominant players until the government is forced to step in and reset the market conditions — a fate generally to be avoided (see: financial crisis).
There are two points here: first, we need to be more liberal and accommodating with how people are able to assert identity online and second, I think that people will learn or develop ways to recall or present their identity through means that are scalable and global.
Consider this progression:
- What’s your address?
- What’s your phone number?
- What’s your AOL screenname?
- What’s your email address?
- What’s your MySpace?
- …Twitter?
- Are you on Facebook?
- What’s your OpenID?
If we develop OpenID such that it can encompass all the previous generations of identifiers, then I think we will make considerable progress. Nothing about OpenID says that it has to start as a URL — only that it has to be compatible with the architecture of the web.
And this is why standards are so critical for establishing how identity is “achieved” on the web. Without standardizing — and achieving ubiquitous adoption of the enabling technologies — the social web will not take shape, limiting us to competition at a much less compelling layer of user experience and service.

Consider email — made possible by SMTP and IMAP. Without these protocols, Gmail would never have had a chance at making it out the door, preventing the kind of compelling experience that they built for the iPhone from ever seeing the light of day. Though these protocols have been in existence for decades, it took someone like Google to come along and really revolutionize the way that people experience email. Anyone could have done it before (and indeed others tried) because the technologies are open and free to implement.
Similarly, I would argue that Twitter is the beneficiary of coming into being right at the moment when SMS finally achieved mass adoption (and awareness) in the United States. Up until that point, the standard was certainly in use by phone carriers, but no one thought to use the ubiquity of SMS as a publishing protocol. Twitter instantly became the everyman blogging tool because you could twitter from your phone, without even having to master the English language (i.e. i can has lolz?) and, perhaps more importantly, without having to know what XML-RPC was.
Ev Williams did the same thing with Blogger back when RSS was just becoming widespread — enabling him to sell the then-novel publishing platform to Google for a hefty sum.
And then there’s Apple.
If I told you that the iPhone was the best example of the success of standards and open source, you’d probably laugh at me, but check it out (click to enlarge):
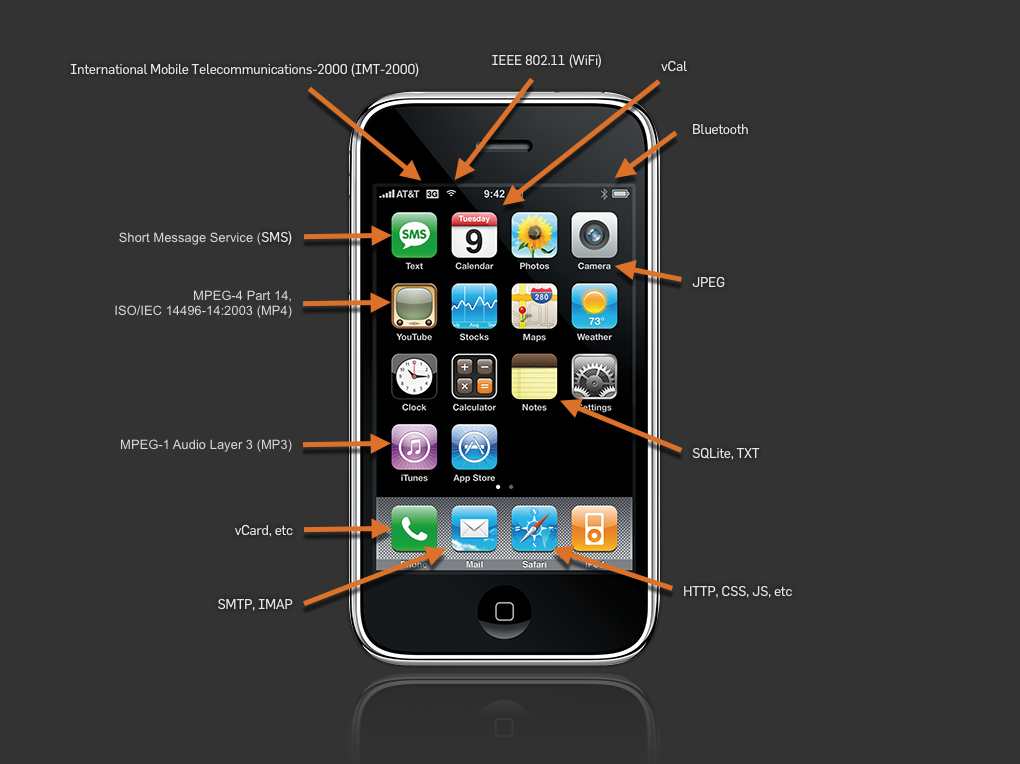
I count at least a dozen standards behind most of the default applications that populate the Home screen. These very same protocols have been available for everyone else to build on top of — and again, indeed people have — but no one else did so with the same degree of execution or emphasis on user experience. I remember the days when my mom got her first phone with SMS and I would send her text messages from college. Months later when I visited her in person she asked me, “Chris, I can’t figure it out. What is this envelope icon on my phone?” How far we’ve come. Moreover, how much Apple has done to create a user interface layer for the SMS standard that few had previously taken the time to test.
And it’s not just the iPhone that demonstrates Apple’s benefits from open technologies: the Safari browser on both OS X and the iPhone is powered by the open source WebKit project; curiously Google’s Chrome browser is built on WebKit, as is the Palm Pre, a direct competitor to the iPhone.
It’s this kind of competitive situation that I’m advocating for when I talk about facilitating the creation of the building blocks for the open, social web.
I don’t want companies to continue to waste effort competing on layers that frankly don’t matter. Who cares how your address book works as long as you’re keeping your users safe and not training them to hand out their passwords like confetti? Who cares how your login experience works as long as people can choose how they want to identify themselves to you? Who cares how you send people messages as long as they get through? Etc. Etc.
Once the mechanisms for these kinds of functions become commoditized and based on the same fundamental technologies, then companies can compete on how easy they are to use and the quality of the service offered.
And the whole point of working on open building blocks for the social web is much bigger than just creating more social networks: our challenge is to build technologies that enhance the network and serve people so that they in turn can go and contribute to building better and richer societies.
I can think of few other endeavors that might result in more lasting and widespread benefits than making the raw materials of human connection and knowledge sharing a basic and fundamental property of the web.

much to chew on and as usually greatly worked out. this particularly reverberated :
because in my technology advocacy –and in my struggles to articulate why we need to rethink blogging as a tool for identity aggregation and management– i would have written this slightly different:
this to me is key. we not only need tools that empower the individual in this new digital economy but we need use tech solutions like OpenID or VRM to create a new political paradigm that protects our rights as individuals who are now being compiled, mined, aggregated and distributed as data as well.
Thank you for this very insightful piece. It puts in perspective a small discussion I started about usernames (http://virvie.posterous.com/username-over-domain-name). And in reference to your previous post (‘my name is not a URL’): what would you have done if @chrismessina wasn’t available anymore?
I’m also glad to hear that the DiSo-project is still going on. I’ve been thinking of a possible application once it is in place: a means of hosting a virtual party on your own domain (see http://www.slideshare.net/avanderkrogt/party-at-my-place-for-web-and-beyond-subtitled ). I’m curious to hear what you think about that.
give me a buzz next time you’re coming to Europe. Would like to do something together.
Great stuff, sorry I don’t have time to post a proper response. A lot to talk about here.
Just a quick one – I happened to come across this, seems very related:
Hi, nice posts there 🙂 thank’s for the interesting information
I’ve been developing a “personhood” model for the past several years, and have written generally on the benefits of such a model and the need for a means of securing such. You can begin to explore some of these ideas here.
I’ve been starting to use social media, in all its various forms, in the role of amateur blogger. This is an extremely comprehensive view of the field, so for a beginner like me it’s been a helpful read.