 Michael Moore is a polarizing figure with a mild-mannered way of suggesting some rather far-fetched, ultra-liberal ideas. I find myself often feeling swayed by his emphaticness but more often than not, unconvinced by the logic of his arguments.
Michael Moore is a polarizing figure with a mild-mannered way of suggesting some rather far-fetched, ultra-liberal ideas. I find myself often feeling swayed by his emphaticness but more often than not, unconvinced by the logic of his arguments.
That said, he does from time to time incite a good deal of discourse and discussion, and on the cusp of the bankruptcy of General Motors, he sent around his suggestions to Barack Obama on what should be done with the company, and so I thought I’d reproduce his nine points here, since I largely agree with them:
- Just as President Roosevelt did after the attack on Pearl Harbor, the President must tell the nation that we are at war and we must immediately convert our auto factories to factories that build mass transit vehicles and alternative energy devices. Within months in Flint in 1942, GM halted all car production and immediately used the assembly lines to build planes, tanks and machine guns. The conversion took no time at all. Everyone pitched in. The fascists were defeated.
We are now in a different kind of war — a war that we have conducted against the ecosystem and has been conducted by our very own corporate leaders. This current war has two fronts. One is headquartered in Detroit. The products built in the factories of GM, Ford and Chrysler are some of the greatest weapons of mass destruction responsible for global warming and the melting of our polar icecaps. The things we call “cars” may have been fun to drive, but they are like a million daggers into the heart of Mother Nature. To continue to build them would only lead to the ruin of our species and much of the planet.
The other front in this war is being waged by the oil companies against you and me. They are committed to fleecing us whenever they can, and they have been reckless stewards of the finite amount of oil that is located under the surface of the earth. They know they are sucking it bone dry. And like the lumber tycoons of the early 20th century who didn’t give a damn about future generations as they tore down every forest they could get their hands on, these oil barons are not telling the public what they know to be true — that there are only a few more decades of useable oil on this planet. And as the end days of oil approach us, get ready for some very desperate people willing to kill and be killed just to get their hands on a gallon can of gasoline.
President Obama, now that he has taken control of GM, needs to convert the factories to new and needed uses immediately.
- Don’t put another $30 billion into the coffers of GM to build cars. Instead, use that money to keep the current workforce — and most of those who have been laid off — employed so that they can build the new modes of 21st century transportation. Let them start the conversion work now.
- Announce that we will have bullet trains criss-crossing this country in the next five years. Japan is celebrating the 45th anniversary of its first bullet train this year. Now they have dozens of them. Average speed: 165 mph. Average time a train is late: under 30 seconds. They have had these high speed trains for nearly five decades — and we don’t even have one! The fact that the technology already exists for us to go from New York to L.A. in 17 hours by train, and that we haven’t used it, is criminal. Let’s hire the unemployed to build the new high speed lines all over the country. Chicago to Detroit in less than two hours. Miami to DC in under 7 hours. Denver to Dallas in five and a half. This can be done and done now.
- Initiate a program to put light rail mass transit lines in all our large and medium-sized cities. Build those trains in the GM factories. And hire local people everywhere to install and run this system.
- For people in rural areas not served by the train lines, have the GM plants produce energy efficient clean buses.
- For the time being, have some factories build hybrid or all-electric cars (and batteries). It will take a few years for people to get used to the new ways to transport ourselves, so if we’re going to have automobiles, let’s have kinder, gentler ones. We can be building these next month (do not believe anyone who tells you it will take years to retool the factories — that simply isn’t true).
- Transform some of the empty GM factories to facilities that build windmills, solar panels and other means of alternate forms of energy. We need tens of millions of solar panels right now. And there is an eager and skilled workforce who can build them.
- Provide tax incentives for those who travel by hybrid car or bus or train. Also, credits for those who convert their home to alternative energy.
- To help pay for this, impose a two-dollar tax on every gallon of gasoline. This will get people to switch to more energy saving cars or to use the new rail lines and rail cars the former autoworkers have built for them.
Well, that’s a start. Please, please, please don’t save GM so that a smaller version of it will simply do nothing more than build Chevys or Cadillacs. This is not a long-term solution. Don’t throw bad money into a company whose tailpipe is malfunctioning, causing a strange odor to fill the car.







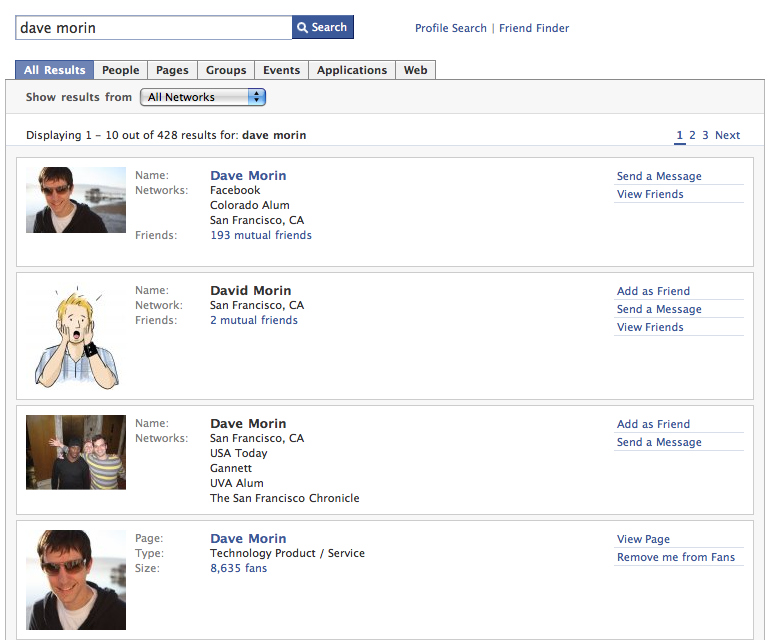
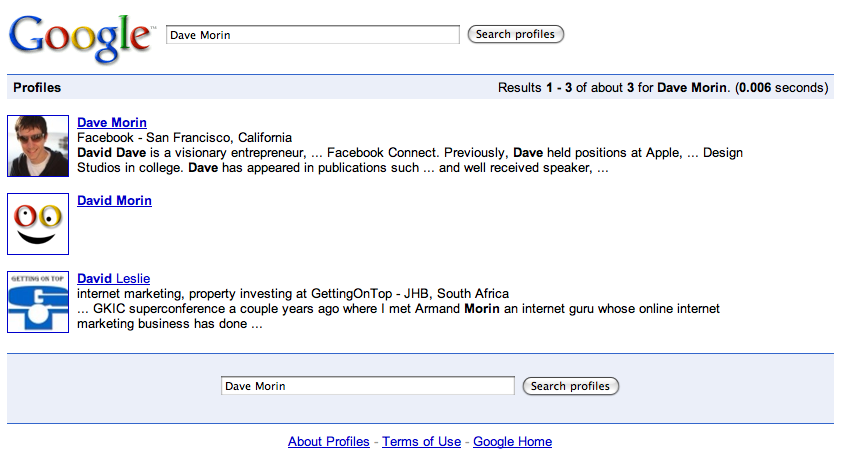








 It’s a frigging button. You can’t mistake it. If you argued that reducing choice increases the likelihood that the user will “get it right” and be able to sign in to your site, you’d be correct.
It’s a frigging button. You can’t mistake it. If you argued that reducing choice increases the likelihood that the user will “get it right” and be able to sign in to your site, you’d be correct.











 That Zuckerberg et al talk about making the web a more “open and social place” where it’s easy to “
That Zuckerberg et al talk about making the web a more “open and social place” where it’s easy to “