I’d originally intended to respond to Joshua Schacter’s post about URL shorteners and how they’re merely the tip of the data iceberg, but since I missed that debate, Google has fortuitously plied me with an even better example by releasing custom profile URLs today.
My point is to reiterate one of Tim O’Reilly’s ever-prescient admonishments about Web 2.0: lock-in can be achieved through owning a namespace. In full:
5. Chief among the future sources of lock in and competitive advantage will be data, whether through increasing returns from user-generated data (eBay, Amazon reviews, audioscrobbler info in last.fm, email/IM/phone traffic data as soon as someone who owns a lot of that data figures out that’s how to use it to enable social networking apps, GPS and other location data), through owning a namespace (Gracenote/CDDB, Network Solutions), or through proprietary file formats (Microsoft Office, iTunes). (“Data is the Intel Inside”)
(I’ll note that the process of getting advantage from data isn’t necessary a case of companies being “evil.” It’s a natural outcome of network effects applied to user contribution. Being first or best, you will attract the most users, and if your application truly harnesses network effects to get better the more people use it, you will eventually build barriers to entry based purely on the difficulty of building another such database from the ground up when there’s already so much value somewhere else. (This is why no one has yet succeeded in displacing eBay. Once someone is at critical mass, it’s really hard to get people to try something else, even if the software is better.) The question of “don’t be evil” will come up when it’s clear that someone who has amassed this kind of market position has to decide what to do with it, and whether or not they stay open at that point.)
Consider two things:
- Google’s mission is to organize the world’s information and make it universally accessible and useful.
- Facebook’s mission is to make it easier for people to share and connect.
Owning the “people” namespace will determine whether people see the web through Google’s technicolor glasses or Facebook’s more nuanced and monochrome blue hues.
Curiously, it has been (correctly) argued that Google “doesn’t get social”, a criticism that I generally support. And yet, with their move to more convenient profile URLs that point to profiles that aggregate content from across the web (beating Facebook to the punch), a bigger (albeit incomplete) picture begins to emerge.
When I blogged that my name is not a URL, I wasn’t so much arguing against vanity or custom profile URLs but instead making the point that such things really should go away over time, from a usability perspective.
Let me put it this way: at one point, if you weren’t in the Yellow Pages, you basically didn’t exist. Now imagine there being several competitors to the Yellow Pages — the Red, Green and Blue Pages — each maintaining overlapping but incomplete listings of people. You’re going to want to use the one that has the most complete, exhaustive and easy-to-use list of names, right? And, I bet beyond that, if one of them was able to make the people that you know and actually care about more accessible to you, you’d pick that one over all the others. And this is where owning — and getting people to “live in” — a namespace begins to reveal its significance.

So, it’s telling thing to look at Google and Facebook’s respective approaches to their people search engines and indexes. Indeed, having a readily accessible index of living persons — structured by their connections to one another — will become a necessary precondition to getting social search right (see Aardvark for a related approach, which connects to the Facebook and IM portions of your social graph to facilitate question answering).
As social search and living through your social graph becomes “the norm” (i.e. with increasing reliance on social filtering), Google and Facebook’s ability to create compelling experiences on top of data about you and who you know will come to define and differentiate them.
To date, Google’s profile search has been rather unloved and passed over, but with the new, more convenient profile URLs and the location of profile search at google.com/profiles, I suspect that Google is finally getting serious about social.
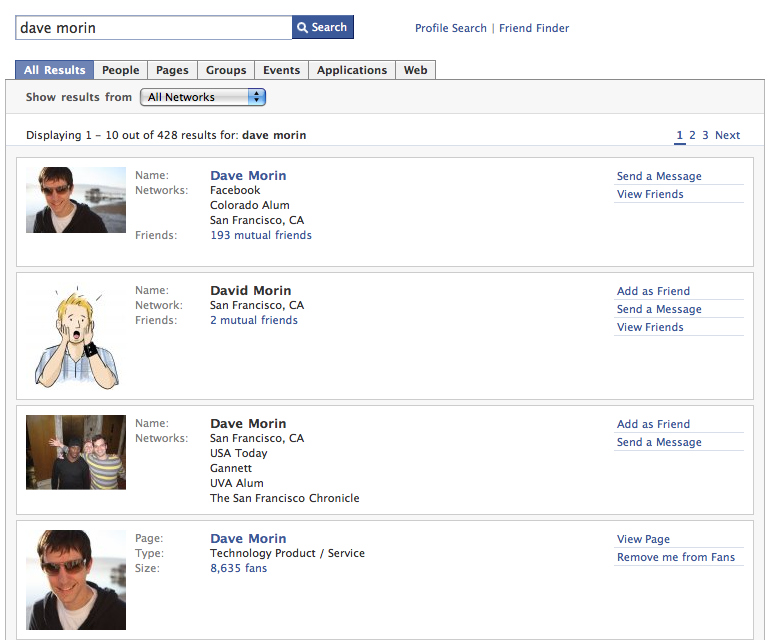
Compare Facebook and Google’s search results for my buddy, Dave Morin:
Facebook logged out:

Facebook logged in:
Google results (there’s no difference between logged in and logged out views):
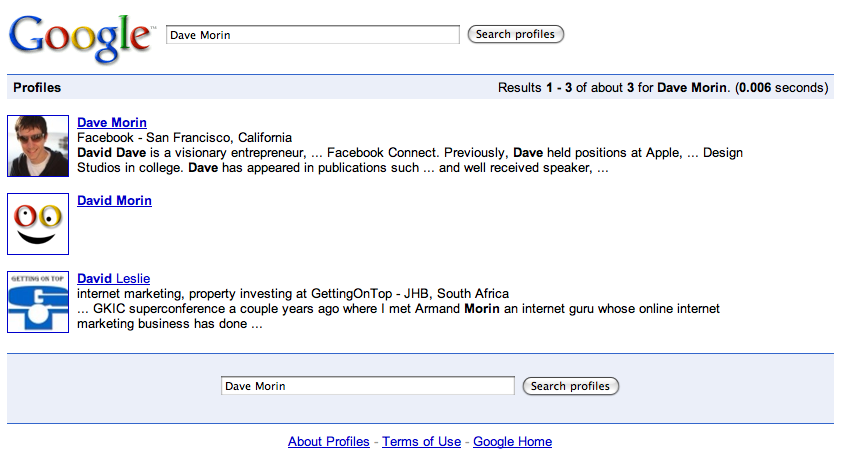
Notice the difference? See how much better Facebook’s search is because it knows which “Dave Morin” is my friend?
Now, consider the profile result when you click through:
Dave’s Facebook profile (logged out):

(Facebook’s logged in profile view is as you’d expect — a typical Facebook profile with stream and wall.)
Now, here’s the clincher. Take a look at Google’s profile for Dave:

Google is able to provide a much richer and simpler profile, that’s much more accessible (without requiring any kind of sign in) because they’ve radically simplified their privacy model on this page (show what you want, and nothing more). Indeed, Google’s made it easier for people to be open — at least with static information — than Facebook!
So much for Facebook’s claim to openness! 😉
Of course, default Google profiles are pretty sparse, but this is just the beginning. (Bonus: both Facebook and Google public profiles support the hcard microformat!)
And the point is: where will you build your online identity? Under whose namespace do you want to exist? (Personally, I choose my own.)
Clearly the battle for the future of the social web is heating up in subtle but significant ways, and Google’s move today shouldn’t be thought of anything less than the opening salvo in moving the battle back to its turf: search.








 That Zuckerberg et al talk about making the web a more “open and social place” where it’s easy to “
That Zuckerberg et al talk about making the web a more “open and social place” where it’s easy to “






 I find it fitting that Ma.gnolia uses an organic symbol as its logo. It has, for all intents and purposes, died.
I find it fitting that Ma.gnolia uses an organic symbol as its logo. It has, for all intents and purposes, died.

