I know I’ve been beating the drum about hashtags for a while. People are either lukewarm to them or are annoyed and hate them. I get it. I do. But for some stupid reason I just can’t leave them alone.
Anyway, today I think I saw a glimmer of the promise of the hashtag concept revealed.
For those of you who have no idea what I’m talking about, consider this status update:

You’ll notice that the update starts out with “#sandiegofire”. That’s a hashtag. The hash is the # symbol and the tag is sandiegofire. Pretty simple.
Why use them? Well, it’s like adding metadata to your updates in a simple and consistent way. They’re not the most beautiful things ever, but they’re pretty easy to use. They also follow Jaiku’s channel convention to some extent, but break it in that you can embed hashtags into your actual post, like so:
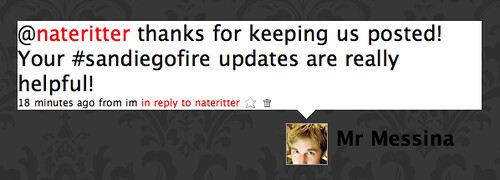
Following the principle of DRY, this simple design means that you can get more mileage out of your 140 characters than you might otherwise if you had to specify your tags separately or in addition to your content.
Anyway, you get the idea.
Hashtags become all the more useful now that Twitter supports the “track” feature. By simply sending ‘track [keyword]‘ to Twitter by IM or SMS, you’ll get real-time updates from across the Twitterverse. It’s actually super useful and highly informative.
Hashtags become even more useful in a time of crisis or emergency as groups can rally around a common term to facilitate tracking, as demonstrated today with the San Diego fires (in fact, it was similar situations around Bay Area earthquakes that lead me to propose hashtags in the first place, as I’d seen people Twittering about earthquakes and felt that we needed a better way to coordinate via Twitter).
Earlier today, my friend Nate Ritter started twittering about the San Diego fires, starting slowly and without any kind of uniformity to his posts. He eventually began prefixing his posts with “San Diego Fires”. Concerned that it would be challenging for folks to track “san diego fires” on Twitter because of inconsistency in using those words together, I wanted to apply hashtags as a mechanism for bringing people together around a common term (that Stowe Boyd incidently calls groupings).
I first checked Flickr’s Hot Tags to see what tag(s) people were already using to describe the fires:

I picked “sandiegofire” — the tag that I thought had the best chance to be widely adopted, and that would also be recognizable in a stream of updates. I pinged Nate and around 4pm with my suggestion, and he started using it. Meanwhile, Dan Tentler (a BarCamp San Diego co-organizer who I met at ETECH last year) was also twittering, blogging and shooting his experience, occasionally using #sandiegofire as his tag. Sometime later Adora (aka Lisa Brewster, another BarCamp San Diego co-organizer) posted a status using the #sandiegofire hashtag.
Had we had a method to disperse the information, we could have let people on Twitter know to track #sandiegofire and to append that hashtag to their updates in order to join in on the tracking stream (for example, KBPS News would have been easier to find had they been using the tag) (I should point out that the Twitter track feature actually ignores the hashmark; it’s useful primarily to denote the tag as metadata in addition to the update itself) .
Fortunately, Michael Calore from Wired picked up the story, but it might have come a little late for the audience that might have benefitted the most (that is, folks with Twitter SMS in or around affected areas).
In any case, hashtags are far from perfect. I have no illusions about this.
But they do represent what I think is a solid convention for coordinating ad-hoc groupings and giving people a way to organize their communications in a way that the tool (Twitter) does not currently afford. They also leave open the possibility for external application development and aggregation, since a Twitter user’s track terms are currently not made public (i.e. there is no way for me to know what other people are tracking across Twitter in the same way that I can see which tags have the most velocity across Flickr). So sure, they need work, but the example of #sandiegofire now should provide a very clear example of the problem I’d like to see solved. Hashtags are my best effort at working on this problem to date; I wonder what better ideas are out there waiting to be proposed?






![Twitter / Mr Messina: how do you feel about using # (pound) for groups. As in #barcamp [msg]?](https://i0.wp.com/static.flickr.com/1410/1236321800_a275c8e8c2.jpg)

